 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFLARE: Diffusion for Hybrid Language Model
Jun 01, 2026Autoregressive (AR) large language models (LLMs) have achieved broad practical success, but sequential decoding remains a key bottleneck for low-latency deployment. Recent efficient-inference work has progressed along two axes: reducing the cost of each model invocation through efficient architectures, and reducing serial decoding steps through parallel generation. Hybrid attention backbones address the former, while diffusion language models (dLLMs) pursue the latter via iterative parallel denoising. Combining these advantages remains challenging: AR-to-dLLM conversion often fails to preserve seed-checkpoint capability, and hybrid-attention recurrent states and masking constraints make diffusion training and serving nontrivial. We present FLARE, a systematic conversion framework for hybrid-attention LLMs. Our analysis identifies transfer data quality as the primary determinant of capability preservation, outweighing loss formulation and attention-mask design. The resulting framework combines a token-equal AR-and-diffusion objective, hardware-aware kernels, and unified inference, enabling one checkpoint to support both AR-style verified decoding and diffusion-style parallel denoising. Starting from strong AR checkpoints with limited post-training data, FLARE is competitive with leading open-source dLLMs across model scales and delivers consistent throughput gains over open-source dLLM baselines in single-GPU concurrent serving. Our results further suggest that practical dLLMs are limited not only by decoding algorithms, but also by transfer data quality and the training inefficiency of current block-diffusion objectives, motivating joint design of data, objectives, architectures, and inference systems.
Unsupervised Identification and Removal of Spurious Correlations During Fine-Tuning
May 26, 2026Fine-tuning a pretrained language model on a curated dataset can produce spurious correlations between the fine-tuning task and unintended latent factors -- such as misaligned personas or political slant -- that the curation procedure has entangled with the task. The model can latch onto these spurious correlations, leading to bias and reduced out-of-distribution generalisation. We prove that under reasonable assumptions on task complexity and the spurious correlation, such latent factors can be identified, without supervision, from the weights of a naive LoRA fine-tune. Existing approaches to removing bias, such as activation steering, remove identified factors from residual-stream activations, either at inference or during training. We argue, however, that the goal should be to remove the spurious correlation, not the latent factor itself, as the pretrained model may rely on it for genuine task signal. To enable this, we propose GRASP, GRadient projection of Associated Spurious Patterns, which prevents the model from acquiring new reliance on the identified latent factor while preserving any pretrained content along it. We validate on three fine-tuning tasks. The first two involve emergent misalignment, where fine-tuning on a narrow task -- in our case, writing insecure code and giving bad medical advice -- leads to misaligned responses on unrelated topics. Here our method completely removes misalignment in the insecure code case and reduces them by ~5x in the bad medical advice case, beating all baselines in the trade-off between misalignment-reduction and task-preservation. The last is a novel political-bias experiment, where fine-tuning on right-skewed Reddit financial-advice data causes political-lean drift on unrelated topics. Here our method reduces drift by more than half, while improving financial task performance, beating all baselines.
LaViDa-R1: Advancing Reasoning for Unified Multimodal Diffusion Language Models
Feb 15, 2026Diffusion language models (dLLMs) recently emerged as a promising alternative to auto-regressive LLMs. The latest works further extended it to multimodal understanding and generation tasks. In this work, we propose LaViDa-R1, a multimodal, general-purpose reasoning dLLM. Unlike existing works that build reasoning dLLMs through task-specific reinforcement learning, LaViDa-R1 incorporates diverse multimodal understanding and generation tasks in a unified manner. In particular, LaViDa-R1 is built with a novel unified post-training framework that seamlessly integrates supervised finetuning (SFT) and multi-task reinforcement learning (RL). It employs several novel training techniques, including answer-forcing, tree search, and complementary likelihood estimation, to enhance effectiveness and scalability. Extensive experiments demonstrate LaViDa-R1's strong performance on a wide range of multimodal tasks, including visual math reasoning, reason-intensive grounding, and image editing.
Discrete Adjoint Schrödinger Bridge Sampler
Feb 09, 2026Learning discrete neural samplers is challenging due to the lack of gradients and combinatorial complexity. While stochastic optimal control (SOC) and Schrödinger bridge (SB) provide principled solutions, efficient SOC solvers like adjoint matching (AM), which excel in continuous domains, remain unexplored for discrete spaces. We bridge this gap by revealing that the core mechanism of AM is $\mathit{state}\text{-}\mathit{space~agnostic}$, and introduce $\mathbf{discrete~ASBS}$, a unified framework that extends AM and adjoint Schrödinger bridge sampler (ASBS) to discrete spaces. Theoretically, we analyze the optimality conditions of the discrete SB problem and its connection to SOC, identifying a necessary cyclic group structure on the state space to enable this extension. Empirically, discrete ASBS achieves competitive sample quality with significant advantages in training efficiency and scalability.
Rethinking the Design Space of Reinforcement Learning for Diffusion Models: On the Importance of Likelihood Estimation Beyond Loss Design
Feb 04, 2026Reinforcement learning has been widely applied to diffusion and flow models for visual tasks such as text-to-image generation. However, these tasks remain challenging because diffusion models have intractable likelihoods, which creates a barrier for directly applying popular policy-gradient type methods. Existing approaches primarily focus on crafting new objectives built on already heavily engineered LLM objectives, using ad hoc estimators for likelihood, without a thorough investigation into how such estimation affects overall algorithmic performance. In this work, we provide a systematic analysis of the RL design space by disentangling three factors: i) policy-gradient objectives, ii) likelihood estimators, and iii) rollout sampling schemes. We show that adopting an evidence lower bound (ELBO) based model likelihood estimator, computed only from the final generated sample, is the dominant factor enabling effective, efficient, and stable RL optimization, outweighing the impact of the specific policy-gradient loss functional. We validate our findings across multiple reward benchmarks using SD 3.5 Medium, and observe consistent trends across all tasks. Our method improves the GenEval score from 0.24 to 0.95 in 90 GPU hours, which is $4.6\times$ more efficient than FlowGRPO and $2\times$ more efficient than the SOTA method DiffusionNFT without reward hacking.
Prism: Efficient Test-Time Scaling via Hierarchical Search and Self-Verification for Discrete Diffusion Language Models
Feb 02, 2026Inference-time compute has re-emerged as a practical way to improve LLM reasoning. Most test-time scaling (TTS) algorithms rely on autoregressive decoding, which is ill-suited to discrete diffusion language models (dLLMs) due to their parallel decoding over the entire sequence. As a result, developing effective and efficient TTS methods to unlock dLLMs' full generative potential remains an underexplored challenge. To address this, we propose Prism (Pruning, Remasking, and Integrated Self-verification Method), an efficient TTS framework for dLLMs that (i) performs Hierarchical Trajectory Search (HTS) which dynamically prunes and reallocates compute in an early-to-mid denoising window, (ii) introduces Local branching with partial remasking to explore diverse implementations while preserving high-confidence tokens, and (iii) replaces external verifiers with Self-Verified Feedback (SVF) obtained via self-evaluation prompts on intermediate completions. Across four mathematical reasoning and code generation benchmarks on three dLLMs, including LLaDA 8B Instruct, Dream 7B Instruct, and LLaDA 2.0-mini, our Prism achieves a favorable performance-efficiency trade-off, matching best-of-N performance with substantially fewer function evaluations (NFE). The code is released at https://github.com/viiika/Prism.
InternVLA-A1: Unifying Understanding, Generation and Action for Robotic Manipulation
Jan 05, 2026Prevalent Vision-Language-Action (VLA) models are typically built upon Multimodal Large Language Models (MLLMs) and demonstrate exceptional proficiency in semantic understanding, but they inherently lack the capability to deduce physical world dynamics. Consequently, recent approaches have shifted toward World Models, typically formulated via video prediction; however, these methods often suffer from a lack of semantic grounding and exhibit brittleness when handling prediction errors. To synergize semantic understanding with dynamic predictive capabilities, we present InternVLA-A1. This model employs a unified Mixture-of-Transformers architecture, coordinating three experts for scene understanding, visual foresight generation, and action execution. These components interact seamlessly through a unified masked self-attention mechanism. Building upon InternVL3 and Qwen3-VL, we instantiate InternVLA-A1 at 2B and 3B parameter scales. We pre-train these models on hybrid synthetic-real datasets spanning InternData-A1 and Agibot-World, covering over 533M frames. This hybrid training strategy effectively harnesses the diversity of synthetic simulation data while minimizing the sim-to-real gap. We evaluated InternVLA-A1 across 12 real-world robotic tasks and simulation benchmark. It significantly outperforms leading models like pi0 and GR00T N1.5, achieving a 14.5\% improvement in daily tasks and a 40\%-73.3\% boost in dynamic settings, such as conveyor belt sorting.
From Masks to Worlds: A Hitchhiker's Guide to World Models
Oct 23, 2025This is not a typical survey of world models; it is a guide for those who want to build worlds. We do not aim to catalog every paper that has ever mentioned a ``world model". Instead, we follow one clear road: from early masked models that unified representation learning across modalities, to unified architectures that share a single paradigm, then to interactive generative models that close the action-perception loop, and finally to memory-augmented systems that sustain consistent worlds over time. We bypass loosely related branches to focus on the core: the generative heart, the interactive loop, and the memory system. We show that this is the most promising path towards true world models.
Millisecond-Response Tracking and Gazing System for UAVs: A Domestic Solution Based on "Phytium + Cambricon"
Sep 04, 2025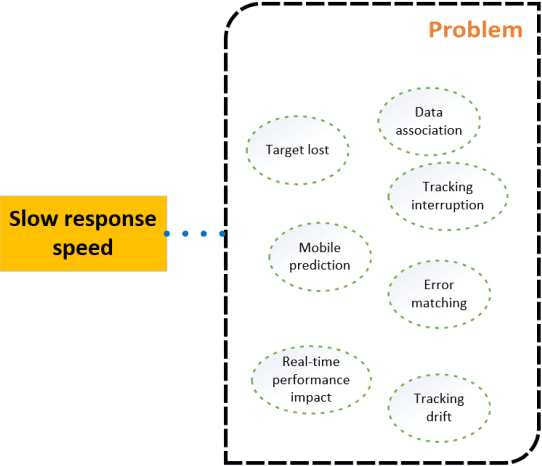

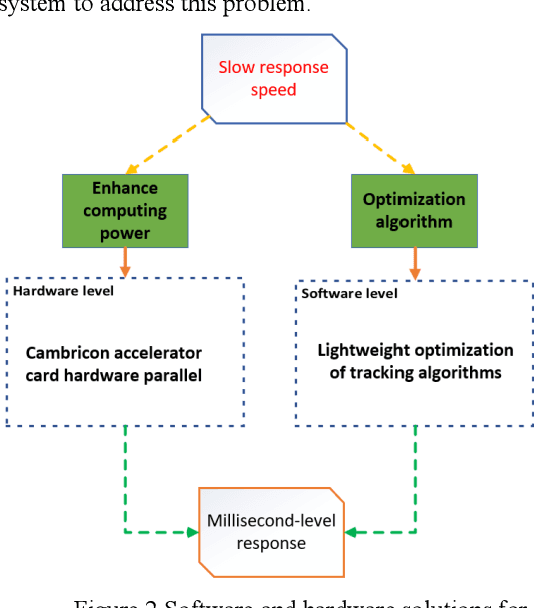

In the frontier research and application of current video surveillance technology, traditional camera systems exhibit significant limitations of response delay exceeding 200 ms in dynamic scenarios due to the insufficient deep feature extraction capability of automatic recognition algorithms and the efficiency bottleneck of computing architectures, failing to meet the real-time requirements in complex scenes. To address this issue, this study proposes a heterogeneous computing architecture based on Phytium processors and Cambricon accelerator cards, constructing a UAV tracking and gazing system with millisecond-level response capability. At the hardware level, the system adopts a collaborative computing architecture of Phytium FT-2000/4 processors and MLU220 accelerator cards, enhancing computing power through multi-card parallelism. At the software level, it innovatively integrates a lightweight YOLOv5s detection network with a DeepSORT cascaded tracking algorithm, forming a closed-loop control chain of "detection-tracking-feedback". Experimental results demonstrate that the system achieves a stable single-frame comprehensive processing delay of 50-100 ms in 1920*1080 resolution video stream processing, with a multi-scale target recognition accuracy of over 98.5%, featuring both low latency and high precision. This study provides an innovative solution for UAV monitoring and the application of domestic chips.
Rethinking Query-based Transformer for Continual Image Segmentation
Jul 10, 2025Class-incremental/Continual image segmentation (CIS) aims to train an image segmenter in stages, where the set of available categories differs at each stage. To leverage the built-in objectness of query-based transformers, which mitigates catastrophic forgetting of mask proposals, current methods often decouple mask generation from the continual learning process. This study, however, identifies two key issues with decoupled frameworks: loss of plasticity and heavy reliance on input data order. To address these, we conduct an in-depth investigation of the built-in objectness and find that highly aggregated image features provide a shortcut for queries to generate masks through simple feature alignment. Based on this, we propose SimCIS, a simple yet powerful baseline for CIS. Its core idea is to directly select image features for query assignment, ensuring "perfect alignment" to preserve objectness, while simultaneously allowing queries to select new classes to promote plasticity. To further combat catastrophic forgetting of categories, we introduce cross-stage consistency in selection and an innovative "visual query"-based replay mechanism. Experiments demonstrate that SimCIS consistently outperforms state-of-the-art methods across various segmentation tasks, settings, splits, and input data orders. All models and codes will be made publicly available at https://github.com/SooLab/SimCIS.